이틀 동안 공부한 내용이라 두 번 나눠 작성할 예정
01. 웹 스크래핑(크롤링)
웹 스크래핑과 크롤링은 약간 다르지만, 비슷하다.
= 웹에서 데이터를 수집
원리는 무엇일까?
웹사이트에 접속해서 받는 데이터가 사실은 (html과 같은) 코드로 되어 있다.
만약 java script의 ajax를 이용해서 주소를 검색하면 어떻게 될까?
Ajax로 요청하면 결과값이 데이터로 넘어온다.
but, 웹 페이지는?
우리가 웹에다 데이터를 요청하면 전달받는 게 '웹문서'이다. (개발자도구의 page code 형식)
그러면 우리는 그 코드를 해석해서, 원하는 정보를 가져오면 된다.
따라서 scraping 한다는 것은,
= 웹사이트의 코드를 이해해서, 가져온다는 것!
우리가 해야할 것은 무엇일까?
코드를 잘 '해석'해서 내가 원하는 정보가 '어디'에 있는지 보고, 그 '정보'를 가져오는 것이다.
따라서 필요한 것 (공부할 부분)
1) 요청하는 방법 2) 요청해서 받은 문서를 분석하는 방법
02. 웹 스크래핑 실습
주의할 점 :
크롤링 한다
= '프로그램'을 이용해서 '특정 사이트'에 '접속'해서 '데이터를 수집'하는 것이다.
따라서 크롤링을 하면,
사람이 하는 것 보다 빠르고 많이 접속 가능하기에 서비스 사이트들이 부담이 된다. (사용자의 많은 요청)
따라서 크롤링 코드를 작성할 때에는 한 번의 data를 한 번씩 가져오는 단 건의 코드를 작성하는 것을 권장!
[실습] 우리는 yes24의 베스트셀러 책제목을 수집할 것이다.
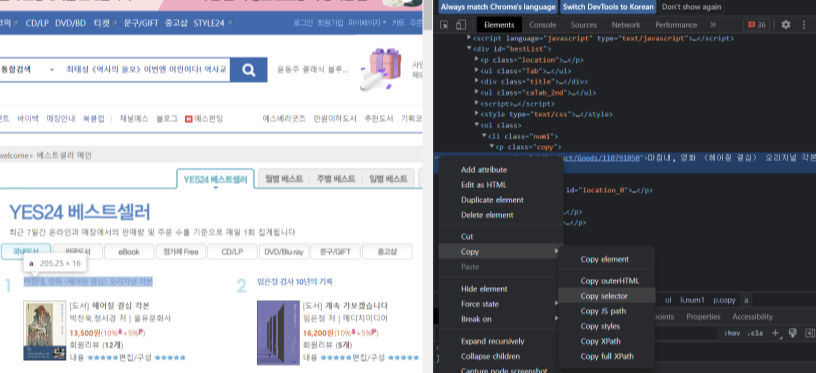
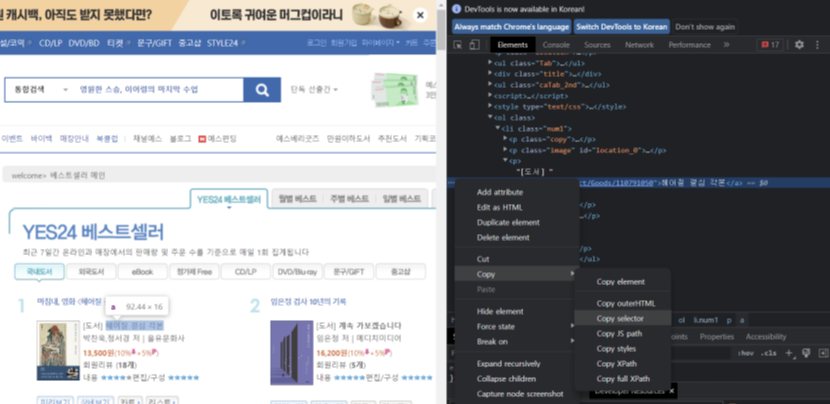
1) 개발자도구 - 책 제목 태그
elements 탭의 좌측상단 마우스 모양을 같이 클릭하고, 책 제목을 눌러야 한다.
그냥 책 제목을 누르면 거기로 들어가진다.

2) a 태그 복사 - Copy
a 태그가 나오고, 이를 복사하는데 우클릭을 하거나 점 세개 ... 를 눌러서 copy
: 이때 copy selector 이용
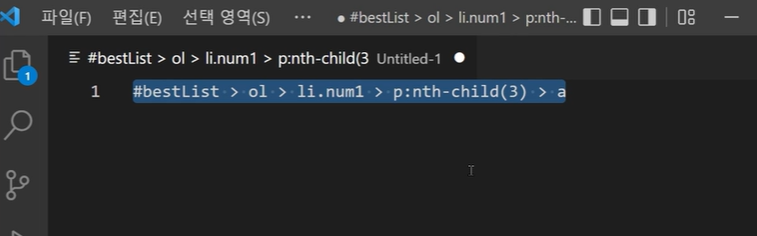
이 코드가 하나의 표현식인 것을 볼 수 있다.
but 우리는 이렇게 하나의 책이 아닌, 전체 베스트 리스트를 가져오고 싶기에 다르게 작성해야 한다.
= 구조를 알면서 코드를 작성해야 한다.
4) 코드 구조 살펴보기
다시 yes24 page 로 돌아와서, 구조 살펴보기
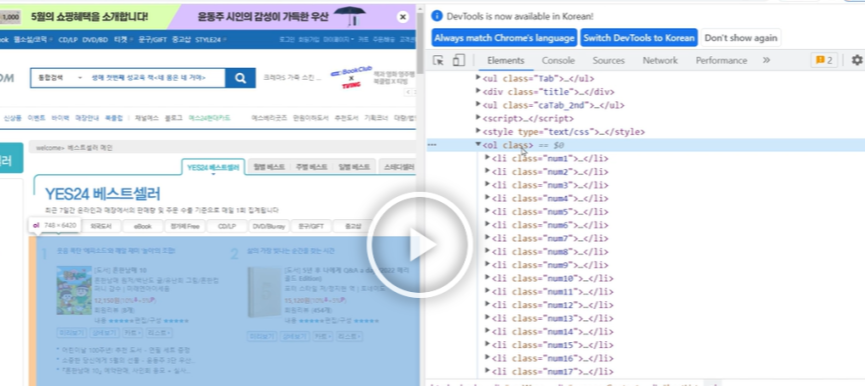
우리가 개발자도구에서 방향키를 움직일때마다, 왼쪽에 어떤 영역인지 볼 수 있다.
= 해당영역이 색칠되면서 보인다.
#bestList > ol
#bestList> ol > li.num1
이를 통해서, 우린 ol 태그를 눌렀을 때 우리가 가져올 전체 데이터가 포함되는 것을 확인할 수 있다.
또한, 각각의 li 태그들은 책 하나하나를 의미하는 것도 파악할 수 있다.
= yes24 웹사이트를 만든 개발자는 베스트셀러를 표현하기 위해 ol 태그를 하나 만들고, 그 안에 순위별로 li 태그들을 만들어둔 것이다.
li 태그들을 자세히 보면, <li class ="num1"> 이라는 식으로 점점 숫자가 커지는 것도 확인할 수 있다. (1-40)
but 자세히 보면 19 ,20이 다르다.
num19_line , num20_line 이렇게 line이 붙어있다.
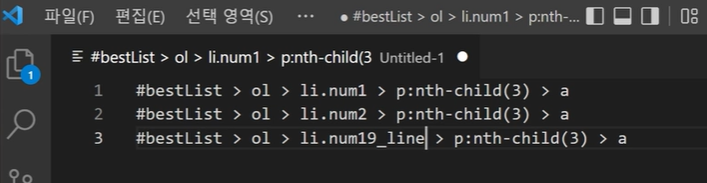
5) 다시 1,2,3을 복사해서 특징을 살펴본다.
#bestList > ol > li.num1 > p:nth-child(3) > a
#bestList > ol > li.num2 > p:nth-child(3) > a
#bestList > ol > li.num3 > p:nth-child(3) > a
규칙이 있고, css에서 한 것과 같은 특징 (li.num1,2,3) 을 발견할 수 있다.
= 즉 우리는 이를 반복문을 통해 처리가 가능하다.
또한 앞에서 데이터를 봤을때, 19,20 번에는 line이 있는 것을 확인하였으므로, 좀 더 정확하게 크롤링이 가능하다.
19, 20번째에는 변경하기
6) VScode로 와서, crawl.py 만들기
7) 터미널을 실행
이때 터미널에 오류가 발생하였음!
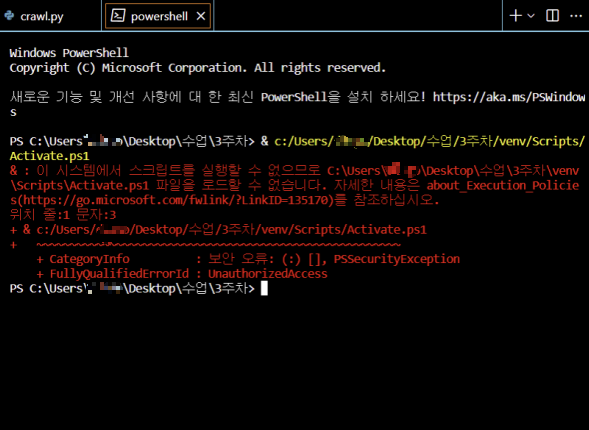
VSCode에서 터미널을 실행했을때 위와같은 문구가 나오면, 스크립트 실행 권한이 제한되어 있는 상태이기 때문이고
이러한 스크립트 실행 권한을 변경하기 위해서는
Windows PowerShell을 관리자 권한으로 실행해서 변경해줘야 한다.
Windows PowerShell을 관리자 권한으로 실행하기
1_ Window10의 경우 시작에서 windows PowerShell을 검색해서 관리자로 실행
2_ 실행된 프로그램에 get-help Set-ExecutionPolicy로 어떤 권한을 설정할 수 있는지 확인 (엔터)
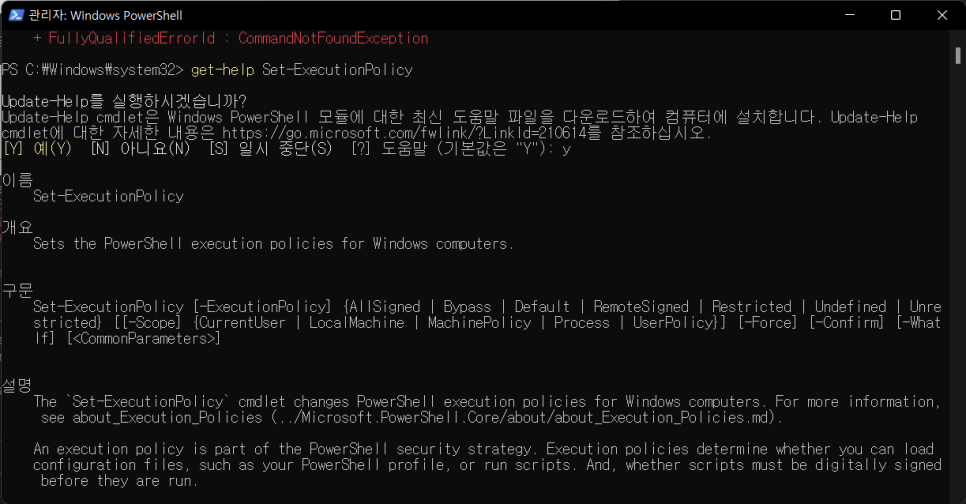
3_ y 입력, Set-ExecutionPolicy RemoteSigned 으로 정책 설정 (엔터)
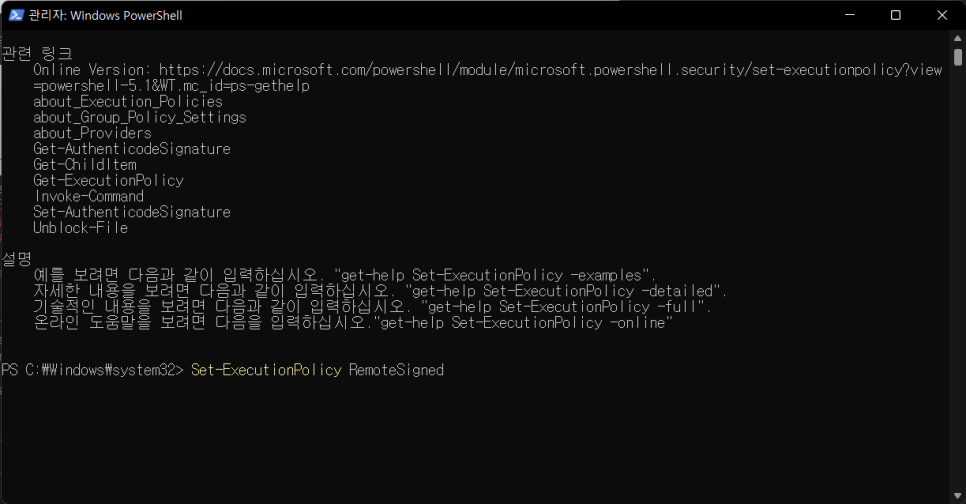
4_ 마지막으로 y를 입력한 후, vscode에 다시 들어가면 오류가 해결된 것을 볼 수 있다.
8) 터미널 - 패키지 설치
이제 터미널로 돌아가서, 패키지 설치하기!
터미널에 pip install beautifulsoup4 입력하기
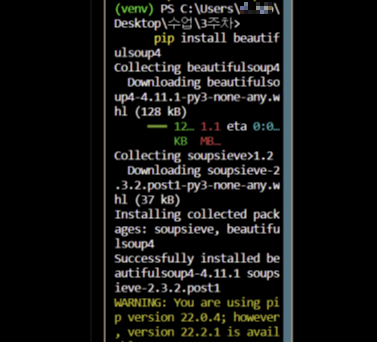
설치가 완료되면, 터미널은 닫아주고 코드를 작성하자.
9) 파이썬 코드 구문 작성 (requests)
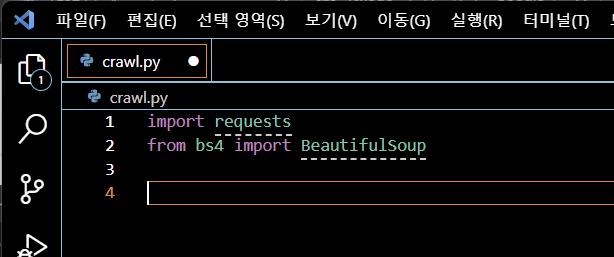
import requests
from bs4 import BeautifulSoup
TIP🤖 import와 from
import는 설치한 패키지 (혹은 파이썬이 기본적으로 가지고 있는 패키지) 들을 가져올 때 사용하는 구문이다.
즉, import를 이용해서 'requests , BeautifulSoup 쓸 것이다' 라는 코드를 작성한 것이다.
from을 쓰는 것은 bs4 (우리가 설치한 BeautifulSoup4 버전이라는 패키지 이름)
그 안에서 '(BeautifulSoup) 을 쓰겠다' 는 의미이다.
한 마디로,
import는 (requests와 BeautifulSoup4) 패키지를 가져오고,
from은 바로 뒤에 입력한 bs4 안에서 사용한다는 것이다.
10) 요청하는 코드 작성 (res 사용)
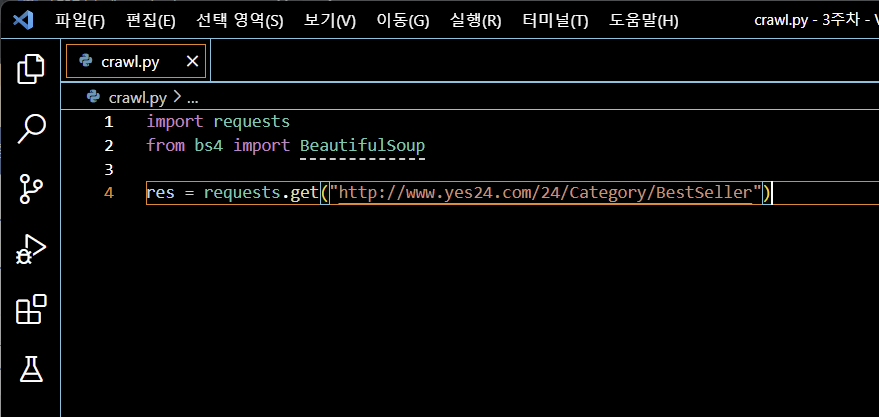
http://www.yes24.com/24/Category/BestSeller 주소 사용requests.get("http://www.yes24.com/24/Category/BestSeller")
11) 출력해보기 (text 사용)
print(res.text)
터미널을 켜보면, 태그가 많이 나오는 것을 볼 수 있다.
12) 분석하는 코드 작성 (BeautifulSoup 사용)
soup = BeautifulSoup(res.text, "html.parser")
BeautifulSoup을 활용해서 만들었고, 그 안에 두개의 값 (res.text, "html.parser") 전달
- res.text
: res 변수가 가지고 있는 text 라는 값 (우리가 주소에 접속하면 받는 html 코드)
- "html.parser"
: BeautifulSoup이 이미 약속을 해놓은 값 (우리가 html 코드로 되어있으니까 분석해달라는 뜻)
> 이렇게 분석을 하면 soup이라는 변수를 이용해서 내가 원하는 태그를 좀 더 쉽게 찾을 수 있다.
(코드를 직접 분석하는 것보다 훨씬 쉽게)
> 태그가 가진 특징을 활용하여 찾을 수 있도록 soup변수가 도와주는 것이다.
13) 변수와 함수 사용
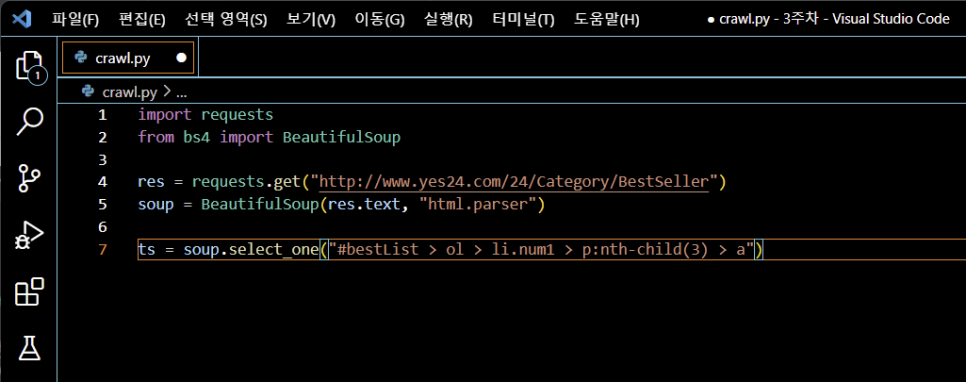
titles라는 변수를 활용, select 함수 사용
select 안에 들어가는 값은 >
#bestList > ol > li.num1 > p:nth-child(3) > a
(첫번째 베스트셀러 제목)
titles = soup.select("#bestList > ol > li.num1 > p:nth-child(3) > a")
> titles를 ts로 변경하기 (이유는..?)
밑을 보면 select_str을 sstr로 변경하는 것과 같은 이치인 듯 하다. 물어보기!
>> 더 편하게 사용하려고 줄인 것이다!
14) 코드 변경 (전체 리스트 가져오기)
그런데 위의 코드는 베스트 셀러 1위의 코드이므로 그 책만을 가져오게 된다.
그렇다면 어떻게 바꿔야할까?
select_one : 조건에 맞는 태그 하나만 가져오겠다는 의미
원래 select 함수는 조건에 맞는 모든 태그를 가져오기 때문에 변경한다.
16) 반복문 사용
그리고 반복문을 사용한다. (파이썬의 for문)
for i in range(40) :
ts = soup.select_one("#bestList > ol > li.num1 > p:nth-child(3) > a")
(책은 총 40권이므로 range (40), : 콜론, 들여쓰기 하기)
그러나 이렇게 변경해도, 아직은 num1 값이므로 1값만 가져오게 된다.
어떻게 변경해야 할까?
17) 반복문 변경
select_one 함수 안에 들어가 있는 '문자열'을 (변수)에 담고 조금씩 바꿔보기
= 모든 값이 나올 수 있도록 반복문 만들어보기
1. sstr 함수에 기존 문자열을 넣고,
2. select_one에는 sstr을 변수로 넣는다.
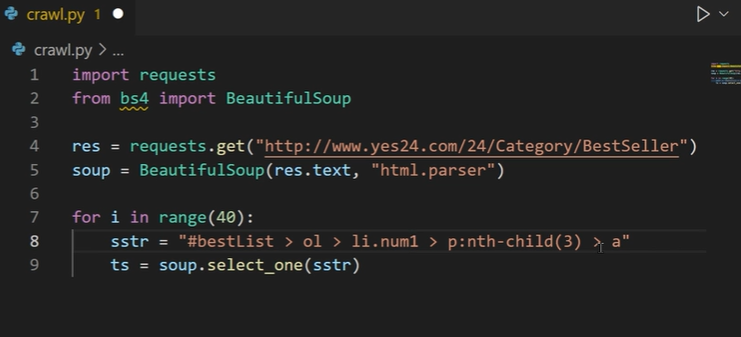
3. 문자열의 1을 지우고 i 덧셈을 한다.
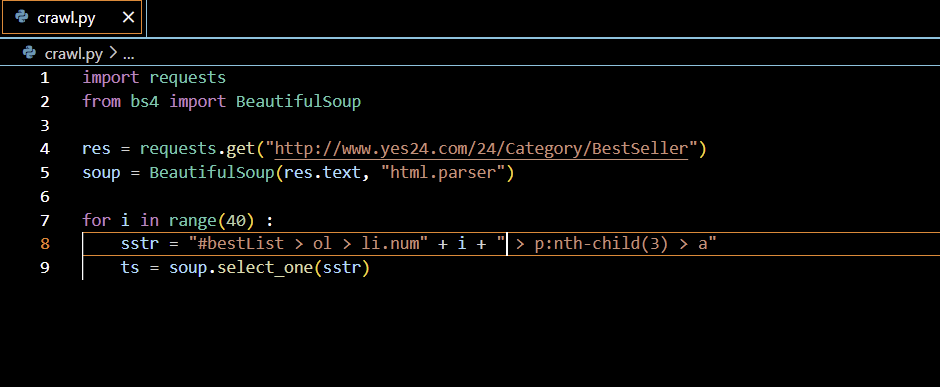
sstr = "#bestList > ol > li.num" + i + " > p:nth-child(3) > a"
그러나 이렇게 하면 오류가 난다.
이는 자바스크립트와 달리 파이썬은 문자열 + 숫자 를 오류라 인식하기 때문이다. (즉, 더할 수 없음)
TIP🤖 주의할 것
그냥 i는 0부터 시작인데, 이 주소는 1부터 시작이므로 i + 1임을 알아야 한다.
또 주의할 것은,
bestlist에서 19,20에는 단순히 숫자가 아니라 문자(line)가 포함되어있으므로 변수를 따로 설정해야 한다.
= 19,20일때는 또 다른 문자열로 변경이 되게 만들기 위함이다.
4. index 변수 만들기 (idx)
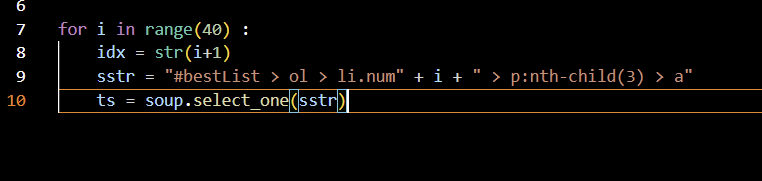
i+1 을 하고, 당연히 str (문자열)로 변경해준다. (이렇게 안하면 덧셈이 안되기 때문이다.)
for i in range(40) :
idx = str(i+1)
sstr = "#bestList > ol > li.num" + i + " > p:nth-child(3) > a"
ts = soup.select_one(sstr)
5. 아까 만든 sstr에서 i 값을 idx로 변경
for i in range(40) :
idx = str(i+1)
sstr = "#bestList > ol > li.num" + idx + " > p:nth-child(3) > a"
ts = soup.select_one(sstr)
18) 조건문 만들기
19,20 같은 특정 조건일때? = 조건문 만들기!
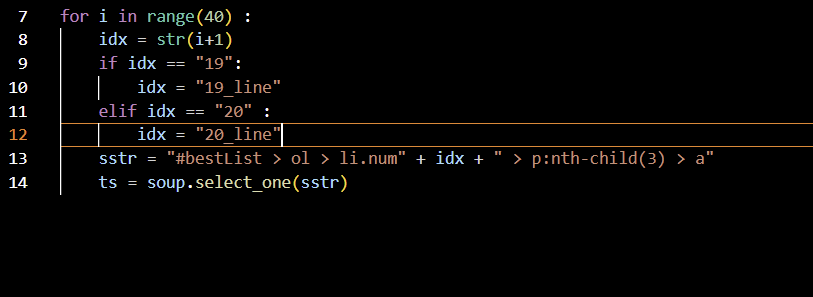
for i in range(40) :
idx = str(i+1)
if idx == "19":
idx = "19_line"
elif idx == "20" :
idx = "20_line"
19일때는 19_line, 20일때는 20_line 을 찾는 조건문이다.
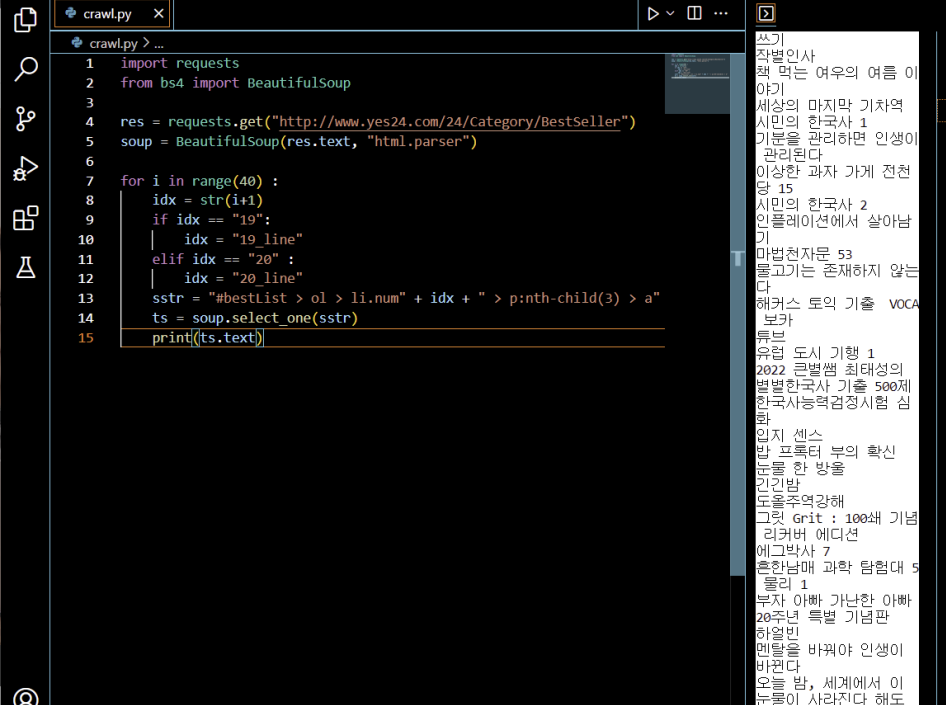
19) 출력을 해보자
print(ts.text)
그리고 재생을 누르면, 터미널에 책 제목이 출력된다
크롤링 실습 끝!
오늘의 소감 ✍️
어제 올렸어야 하는데 강의를 중간에 끊고 다시 들어서, 한 번에 올렸다.
이제 크롤링 실습은 끝났으니 드디어 말로만 듣던 몽고 DB 실습을 진행해볼 예정이다.
일단 화이팅해서 달려보자!
그리고 조교님께서 말씀해주신 자바스크립트와 파이썬의 차이점과
str을 써야하는 중요한 이유는 계속 상기시켜야겠다.
'[부트캠프] IT 코딩 부트캠프 후기 > [Let's TIL😶🌫️] FastCampus' 카테고리의 다른 글
| [Let's TIL✍️] 코딩 18 : 3 Week _ 스터디 (0) | 2022.08.30 |
|---|---|
| [Let's TIL✍️] 코딩 18 : 3 Week _ 서버 만들기 (0) | 2022.08.26 |
| [Let's TIL✍️] 코딩 18 : 3 Week _ 파이썬 기초 (0) | 2022.08.22 |
| [Let's TIL✍️] 코딩 18 : 2 Week _ 오류해결 & 스터디 (0) | 2022.08.22 |
| [Let's TIL✍️] 코딩 18 : 2 Week _ AJAX와 API (0) | 2022.08.22 |



